 Pandas 库
Pandas 库
# Pandas 库
# 为什么要学习pandas
那么问题来了:
numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢?
numpy能够帮我们处理处理数值型数据,但是这还不够, 很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等
比如:我们通过爬虫获取到了存储在数据库中的数据
所以,pandas出现了。
# 什么是Pandas? {#什么是pandas}
Pandas的名称来自于面板数据(panel data)
Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
- 一个强大的分析和操作大型结构化数据集所需的工具集
- 基础是NumPy,提供了高性能矩阵的运算
- 提供了大量能够快速便捷地处理数据的函数和方法
- 应用于数据挖掘,数据分析
- 提供数据清洗功能
# 官网
http://pandas.pydata.org/ (opens new window)
# Pandas的数据结构
import pandas as pd
1
Pandas有两个最主要也是最重要的数据结构:Series和DataFrame
# Series
# Series 介绍
# Series
Series是一种一维标记的数组型对象,能够保存任何数据类型(int,str,float,object...),包含了数据标签,称为索引。
- 类似一维数组的对象1,index=['名字','年龄','班级']
- 由数据和索引组成
- 索引(index)在左,数据(values)在右
- 索引是自动创建的

# Series 创建
import pandas as pd
import numpy as np
1
2
2
# 通过list创建
# 2.1 通过list创建
s1 = pd.Series([1,2,3,4,5])
print(s1)
pritn(type(s1))
#pandas.core.series.Series
1
2
3
4
5
2
3
4
5
# 通过数组创建
# 2.2 通过数组创建
arr1 = np.arange(1,6)
print(arr1)
#索引长度和数据长度必须相同。
s2 = pd.Series(arr1,index=['a','b','c','d','e'])
print(s2)
1
2
3
4
5
6
2
3
4
5
6
# 通过字典创建
# 2.3 通过字典创建
dict = {'name':'李宁','age':18,'class':'三班'}
s3 = pd.Series(dict,index = ['name','age','class','sex'])
print(s3)
1
2
3
4
2
3
4
- 练习
"""
@Author :frx
@Time :2021/11/27 15:15
@Version :1.0
"""
import pandas as pd
import numpy as np
#1.通过list创建
s1=pd.Series([1,2,3,4,5])
print(s1)
print(type(s1))
#2.通过数组创建
arr1=np.arange(1,6)
s2=pd.Series(arr1)
print(s2)
s2=pd.Series(arr1,index=['a','b','c','d','e'])
print(s2)
print(s1.values)
print(s1.index)
#3.通过字典来创建
dict={'name':'李宁','age':18,'class':'三班'}
print(dict)
s3=pd.Series(dict,index=['name','age','class']) #指定顺序 #多索引会生成NaN
print(s3)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# Series的基本用法
# isnull 和 notnull 检查缺失值
# 3.1 isnull 和 notnull 检查缺失值
print(s3.isnull()) #判断是否为空 空就是True
print(s3.notnull()) #判断是否不为空 非空True
1
2
3
2
3
# 通过索引获取数据
# 3.2 通过索引获取数据
print(s3.index)
print(s3.values)
1
2
3
2
3
- 下标
#下标
print(s3[0])
1
2
2
- 标签名
#标签名
print(s3['age'])
1
2
2
- 选取多个
print(s3[[1,3]]) #s3[['age','name']]
1
- 切片
#切片
print(s3[1:3])
print(s3['name':'age']) ##标签切片 包含末端数据
1
2
3
2
3
- 布尔索引
print(s2[s2>3])
1
# 索引与数据的对应关系不被运算结果影响
print(s2*2)
print(s2>2)
#输出结果
dtype: object
a 2
b 4
c 6
d 8
e 10
dtype: int32
a False
b False
c True
d True
e True
dtype: bool
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# name 属性
- 对象名:ser_obj.name
- 对象索引名:ser_obj.index.name
#name属性
s2.name='temp' #对象名
s2.index.name='year' #对象索引名
print(s2)
#输出结果
year
a 1
b 2
c 3
d 4
e 5
Name: temp, dtype: int32
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
# head()
print(s2.head())#默认前五行
print(s2.head(3)) #输出前3行
1
2
2
# tail()
print(s2.tail())#默认后五行
print(s2.tail(3)) #默认后三行
1
2
2
# DataFrame
# DataFrame介绍
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同类型的值。DataFrame既有行索引也有列索引,他可以被看做是由Series组成的字典(共用同一个索引),数据是以二维结构存放的。
- 类似多维数组/表格数据(如,excel,R中的data.frame)
- 每列数据可以是不同的类型
- 索引包括列索引和行索引
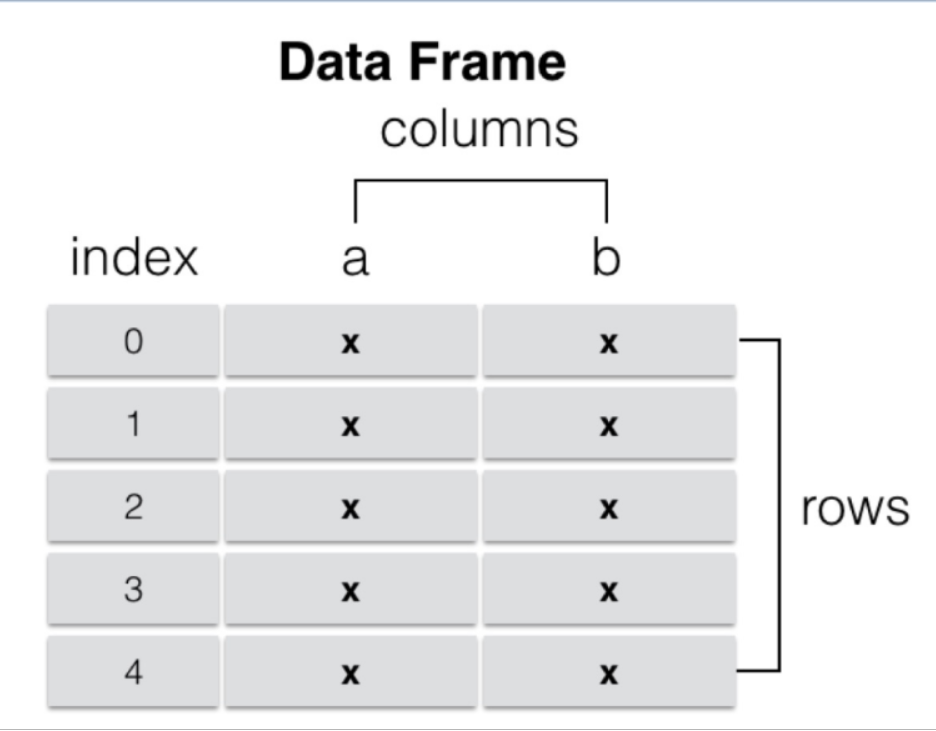
# DataFrame构建
上次更新: 2024/04/21, 09:42:22